从想法到实现
从一个用机器代替人做事的想法到了图灵机模型(一个理论模型)再到后面的具体落地实现 **冯诺依曼体系结构(指出了计算机的一切都是01组合,以及几个基本单元: 控制器,运算器,存储器,IO)再由冯诺依曼体系结构变成了具体的计算机硬件(CPU,内存,硬盘,外设)这个时候机器(计算机)诞生了,**但是如何做事呢?答案是:ISA指令集(CPU制造厂商规定的 01组合),通过01组合操作CPU,再由CPU控制其他硬件完成工作。于是最初的想法到现在就已经实现了,通过计算机(机器)利用 01组合操作,完成任务。**可是问题又产生了,01组合虽然可以操作CPU了但是01这种操作码对于人类而言是很难记忆以及排错的(只要做事就会出错),于是就有了对ISA指令集的抽象,诞生了汇编语言,汇编语言仅仅是对ISA指令集的一个映射,ISA指令集是操作CPU的,(具体点就是CPU中的控制单元)所以汇编语言也是面向CPU的,这就意味着要拿汇编写程序,就得了解CPU的组成(控制单元 运算单元 寄存器单元),为了让写程序更加的简单,或者说能用比较符合人类直觉的语言写出更复杂的程序,就有了对汇编语言的抽象的各种高级语言,比较典型的就是C语言(纯粹的对汇编语言的抽象,没有其他语言特性)高级语言通过编译器或者解释器 屏蔽了开发者对CPU和内存的操作。用符合人类直觉的方式写程序的想法就实现了
让我们简单的设计一门高级语言
接上文我们已经知道了,高级语言之下还有汇编语言以及更加底层的机器语言(ISA指令集)我们知道高级语言会通过编译器或者解释器直接或者间接(先转成汇编)转换成机器语言。所以我们要设计一门高级语言,就得明白机器语言怎么干事的,机器语言是一堆01的组合,但是组合不是杂乱的组合,而是约束的组合,比如 32位指令,规定哪几位是用来定义操作的,哪几位是数据。我们也知道,汇编语言只是对机器语言的映射,比如 add a 1 要表达的意思是 对内存a中的值加一,这里的 add 就是一个操作称为操作码,而a,1这些就是要操作的数据称为操作数,因为映射关系,机器语言也是存在操作码和操作数的。所以我们设计的高级语言至少得对操作数和操作码进行抽象变成符合人类的直觉。首先看操作数,操作数真的全是数据吗?答案并不是,操作数也包括寄存器和内存空间,所以对操作数抽象我们就得抽象数据和空间,于是高级语言的类型系统就诞生了,比如 int ,char,double等等,用这些类型来抽象空间的大小,比如 int占用4个字节。至于数据的抽象和汇编语言中一样,可以是常量可以是存储在内存中的数据。这个插个题外话 寄存器 + 缓存 + 内存 + 硬盘 这些统称为储存系统。为什么会这样安排,是因为在提升性能的同时又要节约成本,这就是为什么寄存器的大小 比内存小的多。好,说回正题,操作数我们抽象了,那么我们看看操作码,操作码定义的是动作,正如 add a 1 虽然能理解,但是不符合人类直觉,所以我们将其抽象成 a = a+1 ,不错,符合人类直觉了,不止如此,我们将 div mov jump 等指令都进行抽象 变成了 -,=,if ,while,到这个时候,我们对于汇编语言的抽象就完成了,这个时候我们得到了最纯粹(没有任何语言特性)的高级语言 这就是经典的C语言。而我们认为神秘的C++也不过是增加了自己的语言特性比如面向对象。以上只是我们对其进行抽象,但是如何实现呢?我们从上帝的视角看,知道需要用编译器,可是编译如何实现的呢?这些问题都指向了一个学科编译原理,我们从生活中找例子,从高级语言到汇编语言是否和从英语到中文很类似呢?把编译器想象成一个人,他现在要当翻译官,要把英语翻译成中文,所以他得具备哪些能力呢?第一个就是得会单词(信息的最小单元),然后得会语法(让单词之间互相配合的规则,规定了单词出现在语句中的位置),会了单词和语法,然后自己理解语义,将理解的语义转换成中文,对应到编译器,先把源语言的语句分解,识别出每个保留字,通过规定的语法,得出合适的语义,在把语义翻译成目标语言。
编译也分前端和后端?
接上文我们已经知道了,编译和现实生活中的翻译很类似,对于人而言,翻译英文到中文,需要理解英语的单词(表示信息的最小单元)以及语法(将信息有约束的串起来)通过单词和语法我们就能明白这句英文的语义
有了语义之后,我们就能很轻松的翻译成中文了。举个例子,I play basketball 首先我们得将每个单词都认识,根据语法理解出语义(相信你的脑海中一定有一副画面:一个人在打篮球 这就是语义)于是你将这个画面用中文描述出来 -- 我在打篮球 这就是我们人类的翻译过程。我们来总结一下,这里大致涉及到了哪几个过程 1.词法分析(理解单词的意思和词性)2.语法分析 (组成句子的单词排列是否符合规则)3.语义分析(根据单词意思和语法规则(比如英语中的固定搭配)形成画面)4.翻译成目标语言 编译的过程同样如此,首先一段程序通过字符流来到词法分析器形成单词流(标识了词性)然后单词流来到语法分析器根据规则进行语法检查,并将单词利用树形结构关联起来,形成语法树将语法树交给语义分析器得到一颗有语义的语法树然后生成了中间结果(IR)(也就是我们脑海中的画面)根据生成的中间结果,以及目标语言的语法 生成目标语言。然后我们将得到中间结果之前的步骤叫做前端 中间结果之后的步骤叫做**后端,**总结一下,前端的工作就是根据源语言生成中间结果,后端的工作就是根据中间结果翻译成目标语言,插个题外话,这和开发中的前后端思想不是完全一样吗?前端根据API写界面,后端根据API提供数据,这里的API可以是json ,可以是xml,也可以是csv,只要定义好了,前后端就可以同时开工,大大提高效率,这里的API和编译过程中的中间结果不是很相似吗?好,说回正题,后端只关心中间结果,不关系源语言,所以从理论上来说任何语言都可以在JVM上运行,因为只要通过前端能过生成JVM能识别的中间结果(字节码)那么就可以跑在JVM上,其实有几门语言就是这个思路,比如 kotlin parse missinggroovy parse missingscala其实有一个项目叫做 GraalVM 就是借鉴了编译过程的思路,让常用的语言(包括C 和C++)跑在了JVM上。https://www.graalvm.org/ 有兴趣大家可以看一看。可能我们会好奇,无论是编译过程还是开发,都会分出前端和后端,这是为什么呢?我的理解是职责分离。前端只负责生成中间结果,后端只负责生成目标语言。前端只负责根据接口写界面,后端只负责根据接口提供数据。
让我们为高级语言增加点新特性?
接上文,我们已经知道了编译的大致过程源语言通过编译的前端生成中间结果,把生成的中间结果交给后端进行分析和优化形成机器码(ISA),我们都知道CPU能执行的只能是机器码(ISA),所以高级语言的执行底层还是会变成机器码来执行,而机器码的规定是CPU制造厂商,那高级语言的新特性怎么出来的呢?总不能让CPU厂商去适配吧。于是只能在编译的过程中做手脚,比如我想增加一个特性 2<x<10 这个表示的意思:变量x在 2~10之间,大家都知道,这个表达式在C语言和Java中是错误的(至少不是我这里要表达的意思),但是我如果要增加这个特性,怎么增加呢?我们知道中间结果(IR)是已经具备了源程序的语义了,所以我们只能在产生IR之前的部分做手脚,也就是编译的前端。只要编译的前端能够识别源语言的这种特性,先通过语法分析能够识别到这种语法是正确的,再通过语义分析,分析出 2<x<10 要表达的意思然后再生成对应的IR。于是我们可以总结出语言的新特性是面向编译器的。我们都知道C语言是有标准的,叫做 ANSI C,但是熟悉C语言的朋友应该也知道GNU C, 这两者有什么关系呢,ANSI C是一个通用的标准,而 GNU C 在标准C的基础上增加了很多新特性。而这些就是靠编译器实现的,关于C的编译套件,最出名的莫过于 GCC 和 LLVM
那他们有什么关系呢,竞争关系,熟悉IOS开发的朋友都知道开发IOS程序需要用到 OC 和 Swift 而在当时 苹果公司想为OC增加新特性,这时候需要编译器的支持,就去找GCC的团队,可是GCC的团队没有理会苹果,于是苹果看到了还是萌芽期LLVM,就把LLVM的创建者拉入苹果公司啦,然后就创造出来现在的LLVM,而LLVM的格局很大,它的设计是可插拔式的,模块化的,这样的好处就是高度可定制化。每个模块可以单独拿出来用,也可以根据自己的需要改。而GCC可不是这么设计的,他是耦合在在一起的,错综复杂。而大家熟悉的C-lang就是LLVM的前端,正是因为LLVM的可插拔式,让别人可以只用他的后端,前端可以自己实现,这又在理论上说明了,任何语言都可以通过LLVM的后端编译成机器码,而语言只需要实现能生成LLVM的IR的前端就可以了。这个设计思路和GraalVM很像,只不过GraalVM的后端是直接利用的JVM。所以我们可以总结出GraalVM想要统一字节码的天下,而LLVM想要统一编译器的天下。而字节码也不过这编译过程中的IR,所以两者也是竞争关系。
解释器 And 编译器 In Java
接上文,我们已经对编译过程有了更加深入的了解了,源语言 -> 编译前端 -> 中间结果(IR)-> 编译后端 -> 目标语言。而编译器和解释器都是对编译过程的实现。那两者有什么区别呢? 编译器就是一口气把高级语言转化成目标语言(一般是机器码,但是也可以是其他高级语言(我个人认为)),解释器就是要用了,就去转化为目标语言(可以是机器码,可以是高级语言)我们熟悉的C语言就是典型的编译型语言。一口气将程序编译成机器码。那Java是什么语言呢?有人会说半编译型半解释型语言,可是有想过这是为什么呢?这里面就涉及到JVM是如何把字节码翻译成机器码的,JVM通过解释器把字节码解释成C++的代码然后在编译成机器码,在解释执行的过程中通过计数器来记录代码执行的次数,当到达了一定的阈值,会把这段代码编译成机器码,以后用到了这段代码直接用机器码代替,这个过程就是JIT(即时编译)。在执行字节码的过程中涉及到了解释和编译所以即是解释型也是编译型语言。在Java中字节码解释器就是广义上的解释器而模板解释器就是广义上的编译器。
对前文所讲的东西做些验证(LLVM,GCC,GraalVM)
前文我说过,GCC是耦合在一起的,那该如何验证他是耦合在一起的呢?我们换个思路,只要证明他不是模块化的,那他就是耦合在一起的,维基百科中关于部分gcc的介绍:每种语言的编译器都是一个独立的程序,可读取源代码并输出机器码。既然编译器是个独立的程序,那么我们所熟知的编译过程中需要的前端和后端就在一个程序里,我们没法单独用一个。用过gcc的都知道,如果需要看中间结果,需要一些 -操作。所以gcc的前端和后端是耦合的。我又说过LLVM是模块化的,可定制的。首先我们得明白模块化的意思是:一个过程单独抽出来可以当作一个程序。也就是对应的有一条命令,而不是向gcc那样用 -参数来指定。维基百科中关于LLVM的部分介绍:LLVM是一套编译器基础设施项目,为自由软件,以C++写成,包含一系列模块化的编译器组件和工具链,用来开发编译器前端和后端。它是为了任意一种程式语言而写成的程式,利用虚拟技术创造出编译时期、链结时期、执行时期以及“闲置时期”的最佳化。

这些就是llvm的部分指令,这些指令都是一个个单独的程序。所以LLVM是模块化的,你想用那个,就用那个。最后一个就是GraalVM了,我说过他理论上能让全部的语言跑在JVM上,我们该如何验证呢?答案就在它的官网。
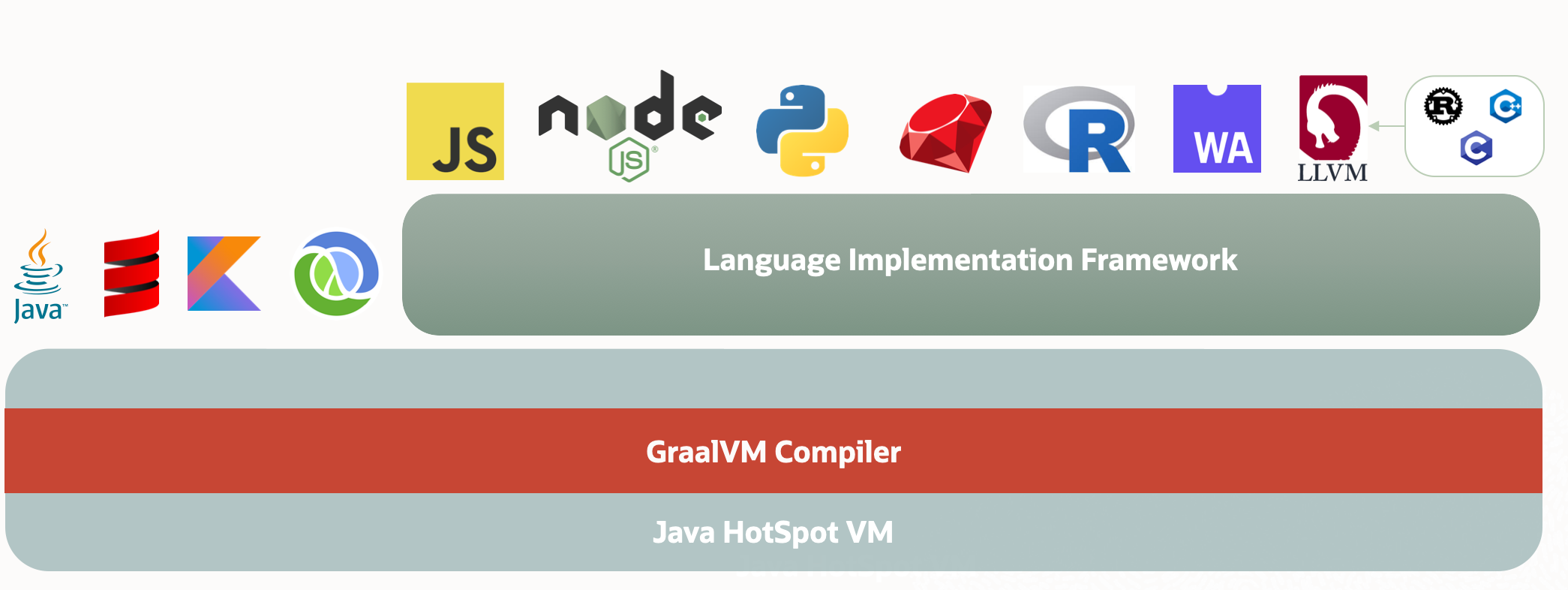
文档中有这么一句话:
In addition to running Java and JVM-based languages, GraalVM’s language implementation framework (Truffle) makes it possible to run JavaScript, Ruby, Python, and a number of other popular languages on the JVM. With GraalVM Truffle, Java and other supported languages can directly interoperate with each other and pass data back and forth in the same memory space.
google翻译:
除了运行 Java 和基于 JVM 的语言之外,GraalVM 的语言实现框架 (Truffle) 使得在 JVM 上运行 JavaScript、Ruby、Python 和许多其他流行语言成为可能。借助 GraalVM Truffle,Java 和其他支持的语言可以直接互操作,并在同一内存空间中来回传递数据。
这样就验证到了几乎所有的语言都可以跑在JVM上。
当然GraalVM也可以不依赖JVM,甚至Java也可以不依赖。这都是靠GraalVM Compiler来实现的
文档中的一段话:
Native Image is an innovative technology that compiles Java code into a standalone native executable or a native shared library. The Java bytecode that is processed during the build of a native executable includes all application classes, dependencies, third party dependent libraries, and any JDK classes that are required. A generated self-contained native executable is specific to each individual operating systems and machine architecture that does not require a JVM.
google翻译:
Native Image 是一种创新技术,可将 Java 代码编译为独立的本机可执行文件或本机共享库。在构建本机可执行文件期间处理的 Java 字节码包括所有应用程序类、依赖项、第三方依赖库以及所需的任何 JDK 类。生成的自包含本机可执行文件特定于不需要 JVM 的每个单独的操作系统和机器架构。
这里再详细的说说GraalVM的架构
GraalVM其实也是对编译过程的实现,主要依靠GraalVM Compiler 以及 Truffle(Language Implementation Framework)各个语言实现GraalVM提供的统一的抽象语法树,然后交过Truffle进行优化和处理,得到的中间结果交过GraalVM Compiler来翻译到具体的机器码或者是字节码,这个执行的过程不就是我们前面讲的编译过程吗?
其实最好的验证方式是看源码。这里只是做了简单的验证。这里我想说说我自己的学习方法,我认为任何东西都可以推理(至少人造物是这样),存在既有理由,还记得学习的三方面吗?why what how ,我认为how固然重要,但是why 和 what 才是how的前提呀,举个例子,学习算法,给我们灌输的理想就是,刷题就好了,可以对于我们开发的来说真的刷题就好了吗?如果不理解 这个算法是什么,出现的原因,以及算法本身的优缺点,我们又如何运用到自己的开发中呢? 我想表达的意思是:刷题固然重要,但是 了解具体算法出现的原因以及本身的优缺点是不可或缺的。
高级编程语言的本质是什么?
接上文,我们详细的说明了编译过程,也了解了 GraalVM这个项目,他们能让几乎全部的高级编程语言跑在JVM上,于是我们就应该明白,编程语言的本质一定是相通的,通过对编译过程的理解,我们知道无论是什么语言,都会最后变成计算机能识别的ISA指令集,我们可以总结出,高级编程语言是对ISA指令集的抽象,准确的说高级编程语言是对汇编语言的抽象,汇编语言是对ISA指令集的抽象,于是我们可以得出,语言没有高低贵贱,本质都是一样的,主要是看应用场景,哪个场景下哪个语言用的爽,有优势就用谁。不仅仅是高级语言,汇编语言也是如此,我们知道ISA指令集是针对CPU的,而CPU可以控制计算机的一切。ISA指令集也可以间接控制计算机的一切。于是我们应该详细了解一下CPU的内部构造了,根据冯诺依曼体系结构,组成计算机的几大件:控制器,运算器,存储器,IO ,而组成电脑的计算机硬件则是CPU,内存,硬盘,外设(IO设备)。通过对比,我们可以得出CPU充当着控制器和运算器的角色。内存和硬盘充当着存储器的角色,但是事实上CPU中也有存储器。比如高速缓存和寄存器。插个题外话,那为什么要这么设计呢?因为速度和成本问题。买过内存的同学应该知道材料越好,速度越快,容量越大的内存,就会越贵。所以我们不得不通过设置多级缓存,来满足CPU的运算速度,同时也能很好的降低成本。所以这样的设计是在性能和成本上做出取舍的结果。好,说回正题,CPU内部的结构大致分为 控制单元 寄存器单元 运算单元(这三者的时钟信号大致一致--可以理解速度一样快)以及高速缓存,于是我们就可以进一步细化,ISA指令集操作控制单元去控制寄存器,将数据交给运算单元,进行CRUD,最后写回缓存或者内存。汇编语言是对ISA指令集的抽象,既然是抽象必定会屏蔽细节,比如,把数据交给运算单元进行运算这个操作被抽象成了 add ,sub 等等,也屏蔽了我们对控制器的感知,比如ISA指令集如何操作控制器去通知寄存器和运算单元的。汇编语言唯一能感知到的就是寄存器。我们知道抽象除了能屏蔽细节,还能提供更加丰富的功能,比如 汇编语言的助记符。于是我们就总结出了汇编语言是面向寄存器的。我们知道计算机的核心思想是图灵机,而图灵机的核心思想:通过不同的状态在纸带上左移或者右移执行程序。(简称状态机),所以汇编语言也必须有这个体现,于是就有了一个专门的寄存器来存储这个状态被称为状态寄存器。一个运行的程序,指令存储在内存中,要执行指令,就要读取指令,而读取指令就需要知道他的地址,于是有一个专门的寄存器存储指令的地址,被叫做指令地址寄存器。
程序在内存中是如何分布的呢?
接上文,我们知道了,汇编语言是面向寄存器的,而寄存器是一个硬件,所以汇编语言是可以控制硬件的,在上文的末尾有讲了两个寄存器,一个是状态寄存器用于存储指令流中跳转的指令地址,一个是指令地址寄存器用于保存当前执行指令的地址。我们都知道,运行中的程序在内存中,可是程序在内存中是怎么分布的我们不得而知。先搞明白如何分布之前,我们先弄清楚如何来表示指令的地址。熟悉的小伙伴都知道,地址一般用16进制表示,但是这是为什么呢?我们都知道最小的寻址单元是byte,假设我们的整个的内存大小为 4GB, 4GB = 4^10^10^10 byte = 2^32 byte 意思是我们有2^32个byte,我们需要唯一标识他们,所以我们需要用 32位二进制来标识他们,于是最小的地址,我们就需要写32个0,这很麻烦,也很浪费空间,于是我们采用16进制,16的一个位可以表示16个信息(0-9 ABCDEF),刚刚好 2^4=16,所以4个二进制位可以表示16个信息,于是16进制的一个位相当于2进制的4个位,所以最小的地址就只需要 8(32/4)个16进制位表示了(0x00000000),插个题外话,为什么一定是16进制呢?反正都是为了书写方便不能是10进制?32进制?(写的更少),我认为书写方便的前提一定是能保证信息的完整性。比如我们采用10进制,他的一位能表示10个信息,但是二进制的几位恰好能表示10个信息呢,2^3=8,2^4=16,如果采用3位一表示,10进制的信息又没用完(8和9没用)采用4位一表示,二进制的信息,他又表示不完整更加不可取。所以10进制只能被否定,那32进制呢?我们同样来推理一番,1位32进制,可以表示32种信息,这个是个缺点,编码集太大了(26个英文字母 + 012345)我们虽然可以用 1位32进制数表示5位二进制数,可是32位的内存地址能被5整除吗?答案肯定不能,所以32进制就被否定了。好,说回正题。我们知道地址使用16进制的数来表示的。所以地址就有高低之分(大小)大的地址叫做高地址,小的地址叫做低地址,最小的叫做低端,最大的叫做高端。说到程序在内存中的分布,我们不得不提一个非常特殊的程序 -- 操作系统,操作系统是个程序所以他肯定在内存中,但是他比较特殊,它的职责就是管理硬件(包括内存),所以我们必须让操作系统的内存,其他的普通程序不能直接访问,于是操作系统的内存要么分布在高端,要么分布在低端。这样可以少控制一个边界。我们知道程序是一条一条的指令,我们不妨叫做指令流,我们一般写程序的时候,会把很复杂的逻辑都写到一个main函数中吗?答案肯定不会,所以我们的指令也不是全都是连续的,他们是分段的。我们给他一个名字叫做指令段(对应着我们程序中的代码段)每个指令段之间都会产生自己私有的数据以及需要和其他指令段共享的数据,于是我们需要两块不同的内存分别存放这些数据,私有的数据有个特点,就是这个指令段执行完毕后,数据没用了,需要销毁,于是我们借助上帝的视角就能明白有种数据结构就能解决这个问题 -- 栈,于是栈顶的数据就是当前执行的指令段产生的私有数据。所以我们把存储指令段私有的数据的内存叫做栈内存。而共享的内存我们叫做堆(和数据结构中的堆没有任何关系这里只是个名字)内存。程序是指令组成,所以我们应该有一块内存是来存储指令的,我们把它叫做代码段。而程序不仅仅在运行过程中会产生数据,在编译的过程中就已经会有数据(常量)比如 public static final name = "pandaer" 这就是常量,这个数据就是放在数据段中的,我们来总结一下,程序在内存中被分为 **栈内存,堆内存,代码段,数据段。**那么他们是怎么分布的呢?一图胜前言。
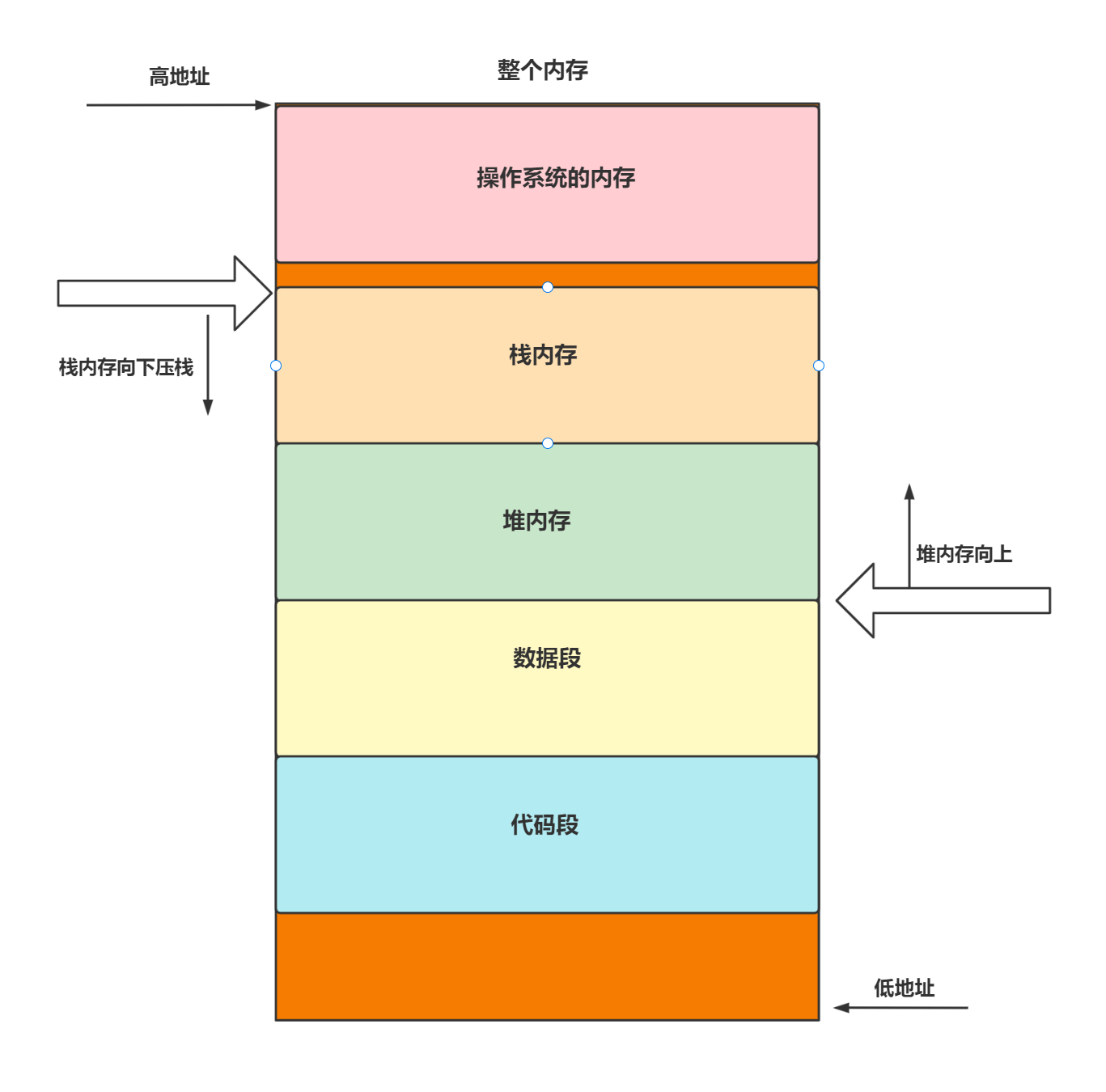
这样分布的好处就是栈内存和堆内存他们始终保持的一定的大小,不会越界。这也就是在递归的时候,深度一大会有堆栈异常。
段寄存器为什么会出现?
接上文,我们明白了程序如何在内存中分布的,栈内存,堆内存,数据段,代码段。我们粗略的描述一下CPU如何控制内存的?答案就是总线,总线分为 数据总线,地址总线,控制总线。控制总线:对硬件单元进行读写等操作的控制,地址总线:用于指定内存中的数据地址,数据总线:用于在CPU和内存中传递要处理的数据。大家都听说过总线的位数和CPU的位数一致。比如 CPU的位数是32位,那么总线的位数也是32位。但是这是为什么,一定要这样吗?我们先来说说为什么?我认为是一致性的问题,我们拿地址总线举例,如果CPU是32位的,而地址总线是64位的。CPU中和内存打交道的其实是寄存器,存储地址的我们已经知道了,叫做地址指令寄存器。他和CPU的位数保持一致,或者说是CPU的位数和他保持一致。地址指令寄存器最多只能存储32位信息,而地址总线可以给我们64位信息,很显然地址指令寄存器接收不了这么多,所以我们可以得出一个小结论,CPU能控制得内存大小是取决于位数的,32位地址指令寄存器有32位信息,又因为最小寻址单元是 byte,所以最多可以有 2^32 个byte = 4 个GB,所以32 位CPU能控制得内存大小是4个G。可是这只是一个地址指令寄存器,如果有两个不就可以表示64位信息了。没错就是这样,所以段寄存器就是因为整个原因而出来的。intel的8086就是这样设计的。
The 8086 has 16-bit registers and a 16-bit external data bus, with 20-bit addressing giving a 1-MByte address space
8086有16位寄存器和16位数据总线和20位地址总线。这个时候地址总线和寄存器的位数不一致。就需要用两个寄存器来表示地址了。而那个额外的表示地址的寄存器被称为段寄存器,那他们是怎么工作的呢。我觉得这个工作的模型和C语言中的二维数组的内存模型一致。C语言中二维数组,他的内存模型还是一维的。只不过是行指针一次偏移的大小不在是1而是列数的大小。而列指针担任了递增的任务。
举个例子比如 int arr[2][3], 行指针i,和列指针j
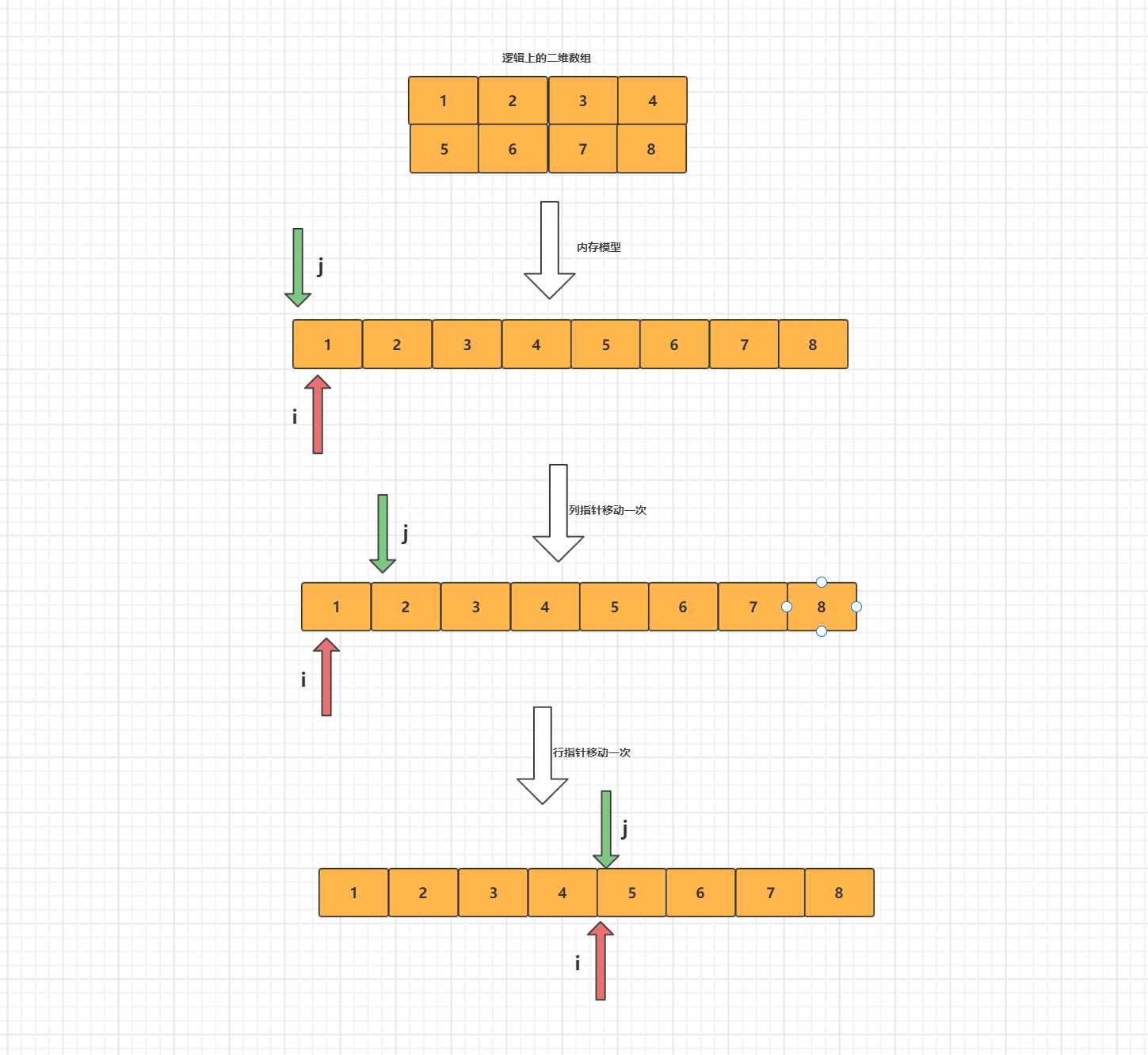
数组的寻址公式 = 首地址 + i*(列数)*size + j*size。段寄存器+指令地址寄存器就是这样工作的,段寄存器就相当于这里的行指针,指令地址寄存器就相当于这里的列指针。内存寻址的公式 = 基地址(段寄存器的值)+ 偏移量(指令地址寄存器的值)换句话说,就是将内存分段,段寄存器保存现在在第几段,而指令地址寄存器用来表示这一段中得地址。
所以我们就可以回答一个问题了,总线的位数一定要与CPU的位数一致吗?答案是不用,但是代价也会随着变大。于是我们就可以回答标题的问题了,为什么段寄存器会出现,因为总线的位数和CPU的位数不一致,或者说需要控制的内存大小比CPU能控制得内存大小大。这种段寄存器+指令地址寄存器来进行内存寻址的模式被称为实模式。
为什么需要保护模式?
接上文,我们知道了段寄存器 + 指令地址寄存器用来访问真实的内存地址,这种内存的寻址的方式被叫做实模式,这个模式能访问真实的内存地址,换句话说,内存中的各个程序是互相可见的包括操作系统,能被其他程序访问和修改,我们都知道操作系统也在内存中,而操作系统是控制CPU的,CPU又控制其他硬件,所以操作系统可以控制一切,如果我们修改操作系统的内存的数据或者指令,那我们就可以控制硬件。这显然是不安全的。于是就出现了保护模式,让每个应用程序都感知不到其他应用程序的存在,换句话说,在一个普通应用程序的视角中,占用内存的除了自己就还剩操作系统了。通过这种方式让每个普通的应用程序都天真的以为,除了操作系统占用的内存,其他的内存,我都可以操控。举个例子,物理内存是4G, 操作系统占用的内存为高1G(从高地址开始的1G大小),剩下的3G都是那个应用程序的。这个只是普通应用程序的视角。我们来看看操作系统的视角,在操作系统的视角中,内存中分布着很多应用程序。在普通程序的视角中,能看见的只有自己和操作系统,但是实际并不是这样的。为了将这两个视角看到的内存进行映射,需要有一个中间人来做转换,而这个中间人就是操作系统。在操作系统中,有一个 GDT(全局描述符表) 这个表,这个表的作用就是映射。把应用程序视角下的内存地址(虚拟地址)映射到操作系统视角下的内存地址(真实地址),并且做段界限检查以及**段的权限检查,**比如是否可写,可执行。而存储这张表首地址的寄存器叫做 GDTR(全局描述符表寄存器)。那么问题来了,既然在一个普通的应用程序的眼中,除了自己就是操作系统,如果能控制操作系统的内存,那么上面所作的努力不就白费了,于是就出现了特权级,特权级低的无法操作特权级高的。总结一下:保护模式的核心思想:通过虚拟内存 + 特权级在得到真实内存地址之前做内存地址合法性检查从而保证了各个应用程序之间互不干扰。
Intel中的保护模式的具体实现(32位CPU)
接上文,我们明白了保护模式的意义,也大致了解了保护模式的机制。可是这是如何实现的呢?现在以32位IntelCPU为例,来了解保护模式的具体过程。我们需要明白的是**无论是实模式还是保护模式都是对物理内存寻址的一种方式。在前面说过,段寄存器的出现是为了能让CPU能控制超出他控制范围之外的内存空间,这是他在那个时代出现的原因,但是到了32位的时代,他的作用开始出现了变化。32位CPU的寄存器位数和总线位数(地址总线,数据总线,控制总线)都是一致的。这个时候32位地址指令寄存器就能够完全寻址完地址总线所控制的内存(4GB),这个时候,段寄存器是否就没用了呢?貌似是这样的,但是保护模式的出现让他有了新的职责。不过在讨论他新的职责的时候,我们来给段寄存器分分类,我们知道,程序在内存中的分布是这样的:栈内存,堆内存,数据内存,代码内存。由于整块的物理内存被分成一段一段的。所以我们可以再细分一下,栈内存 --> 栈段,堆内存 --> 堆段,数据内存 --> 数据段,代码内存 --> 代码段。稍微了解过寄存器就知道,寄存器大致分为通用寄存器和专用寄存器。比如地址指令寄存器。所以段寄存器也不列外,也分为了专用和通用:栈段寄存器(SS),数据段寄存器(DS),代码段寄存器(CS),其他通用的寄存器。我们知道保护模式中,需要去查表(GDT),才能得到真正的基地址,**那如何去获取到GDT(段描述符表)?GDT肯定再内存中,在内存中,就肯定有地址,只要我们能找到地址,就可以访问到GDT,有个寄存器就是专门来存储GDT的首地址的,他就是 GDTR(段描述表寄存器)
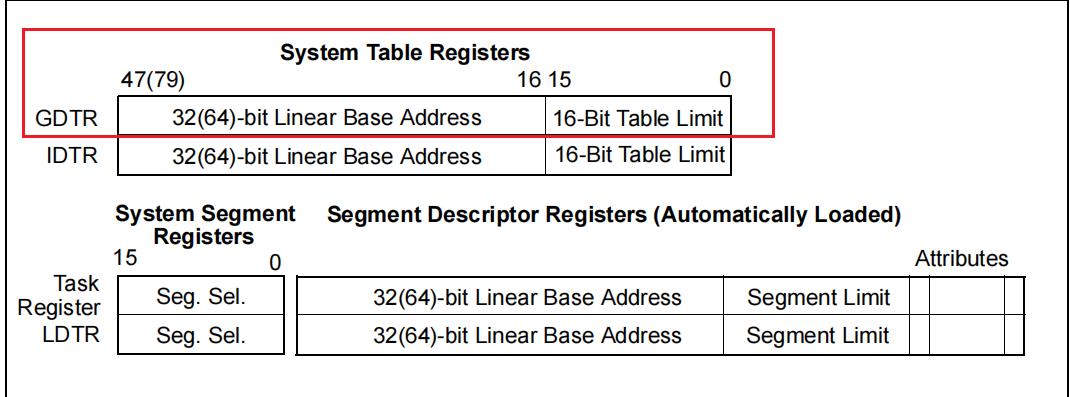
通过上图我们可以知道,GDTR除了有GDT的首地址外,还有16位来表示GDT的长度。好,现在我们有了GDT表了,我们下一步就是在这个表中进行查找,找到我们需要的段内存的基地址。怎么找呢?这个时候段寄存器的新职责就体现了出来。段寄存器中存储着GDT表中的一个下表。段寄存器存储的数据叫做选择子
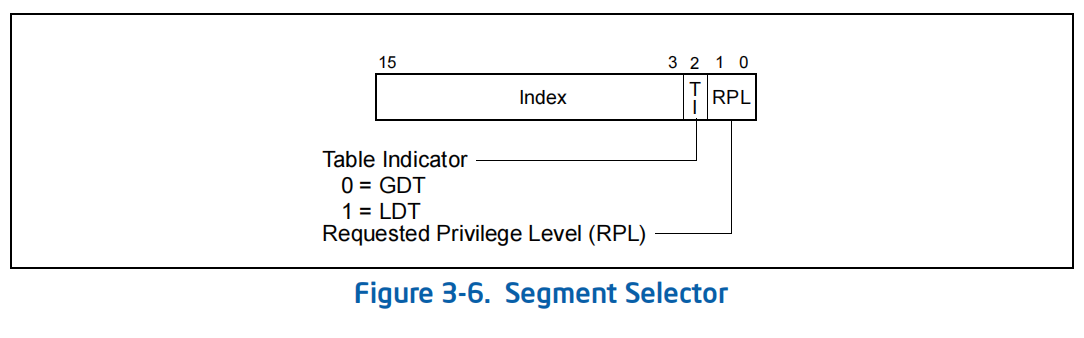
选择子的基本结构:Index -- 表中的索引,TI -- 那张表(这里就是 GDT),RPL -- 就是我们所说的特权级。
现在我们有了选择子,就相当于我们拿到了GDT表中的一个下标了,那么我们就可以找到段描述符了。而段描述符中就有真实的段基地址。

通过图片给出的信息,我们可以看出,段描述符中除了有基地址外,还有Limit--表示这个段的大小,DPL -- 描述符特权级。
现在我们拿到了段描述符,然后通过,段描述符中的基地址 + 偏移量(指令地址寄存器中的值)就访问到了真实的物理地址。
我们来总结一下这个过程:CPU先通过GDTR(段描述符表寄存器)获取到GDT(段描述符表)再通过段寄存器中的选择子,获取到一个GDT的索引,然后通过 GDTR中的首地址 + 索引 获取到一个段描述符,通过比对选择子中的特权级和段描述符中的特权级,是否可以访问,如果可以,通过段描述符中的段基地址 + 偏移量(指令地址寄存器的值)找到真实的物理地址,即某个段的首地址。这就是保护模式在Intel 32位中的具体过程。